04. 代码实现接口测试
2024年10月28日大约 5 分钟
04. 代码实现接口测试
1. 自动化执行接口测试的场景
- 测试目的
- 防止开发修改代码时引入新的问题
- 测试时机
- 开发进行系统测试转测前,可以先进行接口自动化脚本的编写
- 开发进行系统测试转测后,优先进行系统测试用例的执行,再进行接口自动化脚本的编写
- 注意:编写接口自动化脚本和系统测试用例执行没有明确的先后顺序,在项目中系统测试用例执行的优先级更高
- 测试依据
- 自动化执行接口测试的用例可以根据接口设计文档来设计
- 自动化执行接口测试的用例也可以根据环境抓包来设计
2. 基于代码实现接口自动化测试
1. 接口自动化框架设计思路
- 搭建基础框架
- 定义项目目录结构,安装依赖包
- 通用功能类封装
- 数据库工具类、日志处理类封装
- 用例代码实现
- 封装接口对象 + UnitTest框架编写测试脚本
- 数据驱动设计
- 测试数据json文件设计、参数化实现
- 断言处理
- 断言处理
- 用例组织运行
- 组织测试用例运行,测试报告分析
2. 搭建基础框架
目录结构
apiTestP2P ├── api ├── script ├── data ├── report ├── log ├── app.py ├── utils.py └── run_suite.py安装依赖包
安装requests 安装parameterized 安装pymysql 安装HTMLTestReport
3. 通用功能类封装-初始化日志配置
- 日志配置
- 提示:使用Python中的logging日志模块来收集日志,把日志信息输出到控制台和日志文件中
def init_log_config():
# 创建日志器
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# 创建控制台处理器
sh = logging.StreamHandler()
# 创建文件处理器
log_path = BASE_DIR + "/log/p2p.log"
fh = logging.handlers.TimedRotatingFileHandler(log_path, when="midnight", interval=1, backupCount=7, encoding="UTF-8")
# 创建格式化器
f='%(asctime)s %(levelname)s [%(name)s] [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s'
formatter = logging.Formatter(f)
# 把格式化器添加到处理器中
sh.setFormatter(formatter)
fh.setFormatter(formatter)
# 把处理器添加到日志器中
logger.addHandler(sh)
logger.addHandler(fh)4. 通用功能类封装-数据库操作工具类
- 实现的功能
- 获取数据库连接对象方法 get_conn()
- 关闭数据库连接对象 close_conn()
- 查询一条记录 get_one()
- 查询多条记录 get_many()
- 查询全部记录 get_all()
- 更新数据库 uid_db()
5. 用例代码实现
- 测试脚本层
- 根据测试用例文档转化为测试脚本
- 测试脚本层重点关注测试数据准备和断言
- 测试脚本层直接调用接口对象层发送请求
- 接口对象层
- 根据接口API文档封装
- 接口对象层重点关注如何调用接口
- 请求参数需要测试脚本层传递
- 并把响应结果返回给脚本层
测试脚本层 -> 接口对象层
6. 数据驱动
- 定义数据文件
- 定义存放测试数据的目录,目录名称:data
- 分模块定义数据文件
- 根据业务编写用例数据
- 参数化实现
- 读取json文件,构造参数化数据
- 使用parameterized实现参数化
7. 断言处理
封装公共断言
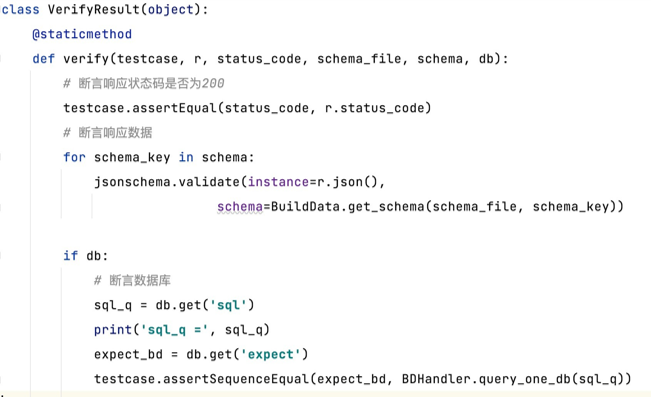
image-20230330190030471
8. 用例组织运行
# 导包
import unittest
from htmltestreport import HTMLTestReport
...
# 创建测试套件
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(TestAdd))
...
# 设置测试报告文件路径
report_path = config.BASE_DIR + "/report/report.html"
# 实例化HTMLTestReport对象
runner = HTMLTestReport(report_path, title="接口自动化测试报告", description="...")
# 执行测试套件
runner.run(suite)9. 定时执行接口测试脚本
- 把脚本提交到代码仓库中
- 配置Jenkins持续集成工具
- 创建构建任务
- 定时触发
- 分析执行结果
3. 扩展BeautifulSoup
掌握如何使用BeautifulSoup解析HTML文档
1. BeautifulSoup介绍
- Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库
- 它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式
- Beautiful Soup会帮你节省数小时甚至数天的工作时间
- Beautiful Soup 3目前已经停止开发,推荐在项目中使用Beautiful Soup 4,简 称BS4.
2. BeautifulSoup安装
pip install beautifulsoup4
注意
- 包的名称为beautifulsoup4而不是BeautifulSoup,BeautifulSoup是Beautiful Soup3的发布版本!
BeautifulSoup-如何使用
提示:通过BeautifulSoup 对象可以获取文档元素的所 有信息
from bs4 import BeautifulSoup soup = BeautifulSoup(open("index.html"), "html.parser") soup = BeautifulSoup("<html>data</html>", "html.parser")说明
- 将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象
- "html.parser":Python标准库中的HTML解析器。BeautifulSoup还支持一 些第三方的解析器,如:lxml、html5lib等,这些第三方解析器需要额外安装
3. BeautifulSoup-基本用法
- ele = soup.标签名
- 根据标签名获取标签对象如果匹配多个元素,则返回第一个
- ele_list = soup.find_all(标签名)
- 根据标签名获取所有匹配的标签
- attr_value = ele.get(属性名)
- 根据标签的属性名获取对应的属性值
- text = ele.get_text()
- 获取标签的文本内容
4. 示例代码
待解析数据
html = """ <html> <head><title>程序员</title></head> <body> <p id="test01">软件测试</p> <p id="test02">2020年</p> <a href="/api.html">接口测试</a> <a href="/web.html">Web自动化测试</a> <a href="/app.html">APP自动化测试</a> </body> </html> """python
from bs4 import BeautifulSoup html = """xxx""" soup = BeautifulSoup(html, "html.parser") print(soup.title) # 获取title标签 print(soup.p) # 获取第一个p标签 print(soup.p.get("id")) # 获取第一个p标签的id属性值 print(soup.find_all("a")) # 获取所有的a标签 # 获取所有的a标签,并遍历打印a标签的href属性值和文本内容 for a in soup.find_all("a"): print("href={} text={}".format(a.get("href"), a.get_text()))